Overview
For this assignment, we were asked to create a chatbot. I decided to go with a Twitter bot as I haven’t really used Twitter a ton over the years (and, frankly, people unfamiliar with chatbots are most likely to extrapolate what I mean when I say “Twitter” then “bot”.)

In a previous position, I spent several years as the e-commerce and marketing manager for a large independent office supply company in San Diego. One of my favorite things about the job was that all the samples came to my desk first and, let me just say, giving out purple pens and odd-shaped post-its brings some of the best feelings in the world. Fact: People love office products… familiar or obscure, these products often touch on something that get people excited. [Disclaimer: I could totally be projecting my enthusiasm on others in this matter.] Being familiar with this type of data and having old lists I complied while making marketing material in my free time still on my hard drive, I thought for my project I’d send out a regularly-timed tweet with a description of an office product to get us through the rest of the year.
Process
So, wow. This project was a doozy. I spent several hours last week looking through the suggested reading materials and videos. This week, I was concerned that getting my Twitter bot set up and posting to Twitter was going to be my biggest issue. Fortunately, we did an in-class demo and that got me set up most of the way.
Where I spent the biggest amount of time was trying to insert a for() loop into my code’s testTweet() async function (which sends out the code) and scrubbing and refining the data set for the project. I can’t say that I fully understand how async and for() loops work together, but I knew from experience that there were only so many places I could insert an iteration for my array in the code, if it was at all possible.
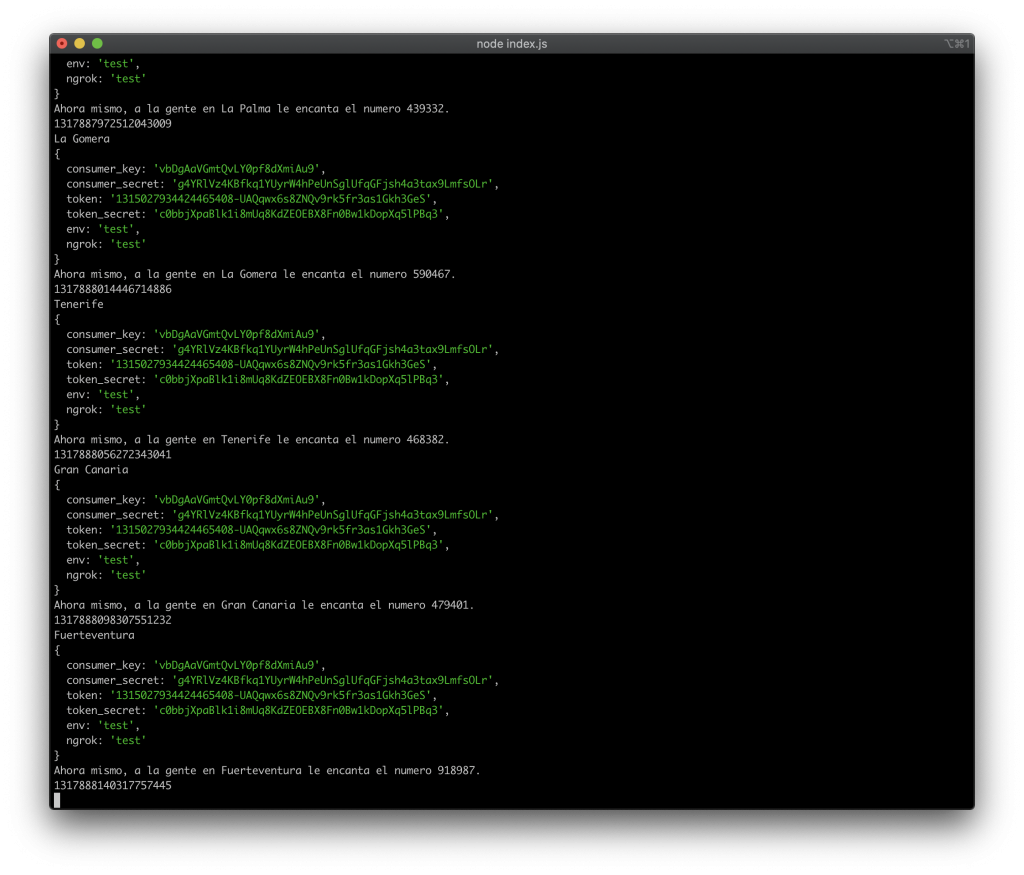
It took about two and a half hours and about 1,043 tweets (whoops!) to get me to where the code was it doing what I wanted it to. Specifically, looping through each item in my array—one at a time, sending out a tweet with the item in the array, then waiting a few minutes for the next item.
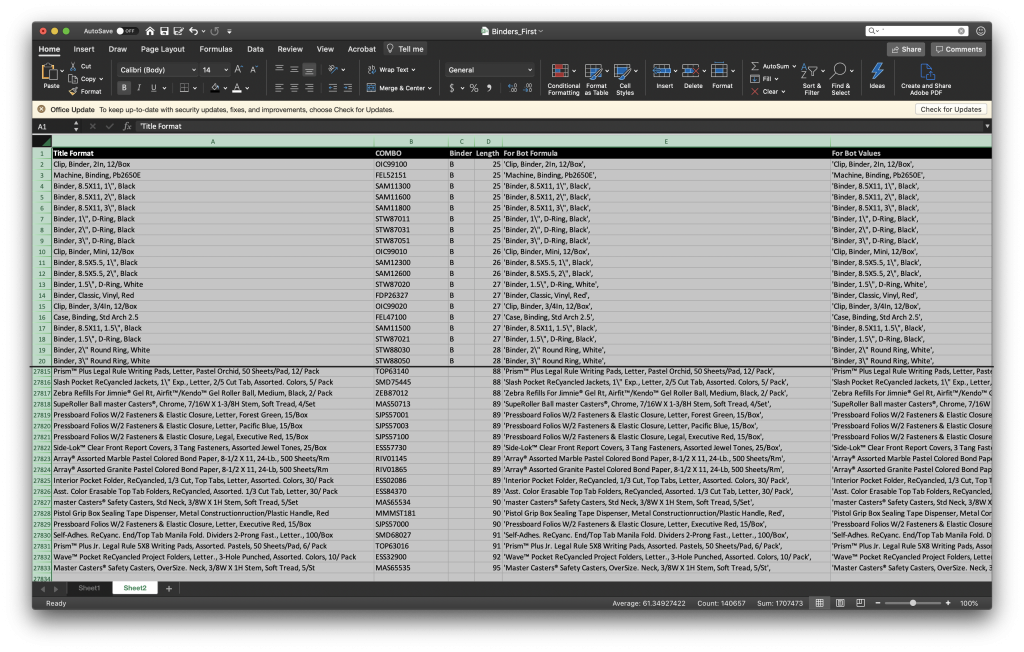
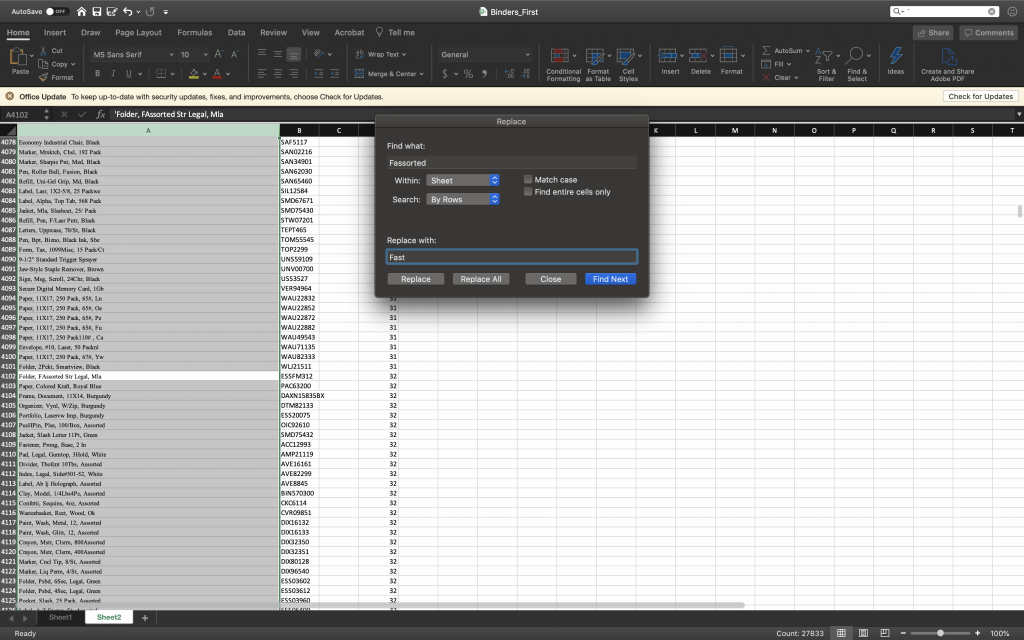
Massaging the data left ME in need of a massage. Hunching over a computer for about 4 hours while working with a ~28,000 line spreadsheet was agonizing; however, not as brutal as realizing that my find-and-replaces had turned words like ‘waste bin’ and ‘fastener’ into ‘wAssortede bin’ and ‘fAssortedener’. I haven’t worked with a dataset so large in years and, in 100 changed instances in 27,000+ lines, it’s easy to miss such changes. Eventually, I realized I also forgot to format the ‘ ‘ ‘ (single quote) out of the array items (like when we use ‘ to mean “feet” in measurements) and had already done so many changes, so I spent a good deal of time scrolling through lines to see what I may have missed. Eventually, I just ended up letting Twitter tell me when my code was bad when I knew I was down to a few bad items in my array… doing this pointed out what patterns I might be able to look for in find and replace to fix other lines.
Once I got the two parts in a good state (the code iterating the array properly and sending tweets at a regular interval) and the dataset (essentially throwing no errors and being combed-through to change noticeable obscure abbreviations like ‘bdgy’—aka burgundy), I decided to put some thought into how to display it.
I thought about what biases might be built into my dataset. Honestly, at face value, I didn’t think much was there. In fact, I see it as commodity-based business, where service it what matters more. That said, the more I thought about it, the more I realized that these items are the tools that are used by those who perpetuate the current system—and, sadly, I know that companies are willing to bend over backwards for people who have money, but accommodating those who are already in a higher position of power. (FYI money == power, unfortunately.) Businesses, like office supply companies, cater to their biggest client. In there, there’s something. The way we do business is definitely part of our existing structure that reinforces unbalanced social dynamics. (For deeper thoughts,, I’ll have to keep sleeping on it.)
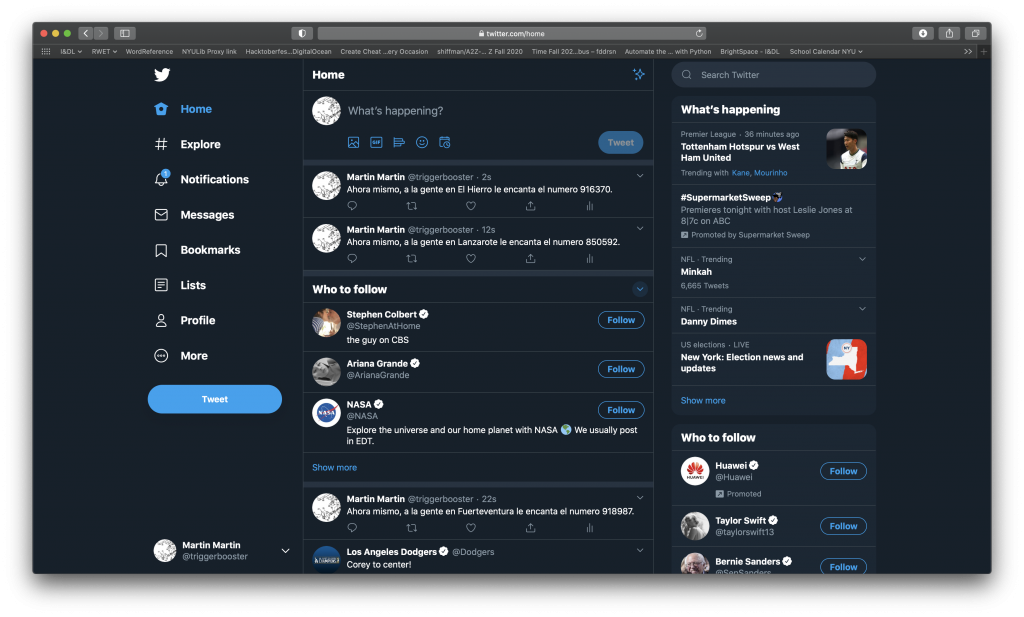
That said, I did make some conscious decisions on the displaying of my tweets and data. First, since my Twitter handle is @triggerbooster, I decided to put items related to trigger boosters together and save them for last… TWO THINGS: ONE, a trigger booster is the name for the piece on the end of a three ring binder that allows you to pop the rings open. I tell you this because the related items I referred to are all things binder-related. And, TWO, I intended to make the binder-related items—all 1,491 of them—appear in a preferential position, but in the end I couldn’t decide if “better” was going first or going last; hence, I went with save the best for last. So the order of these products goes non-binder related, shortest description to longest description (I used LEN(text) in Excel to count the characters), then binder-related (descriptions containing ‘bind’), again, from shortest to longest description.
Since I had the code/data in place and working, I just needed to decide on interval. I went with getting us through 2020 with the 27,832 items. To do that, at 17:45 (NYC time) on 18 October 2020, according to timeanddate.com, there were 106,995 minutes left in 2020. I divided that number by 27,832 to get a result telling me I should send the tweets every 3.8443158954 minutes. I multiplied 3.844 by 60 (to get seconds) and then 1,000 (to get milliseconds) to get me an interval for sending the tweets of 230,640ms. I also gave each tweet a number to help keep track.
Also, I tried speeding up my testing and changed the interval from 10,000ms to 5,000ms and got my application suspended earlier in the day. I emailed them begging for them to reactivate my writing capabilities, but ended up just creating a new ‘application’ in the dev screens when I realized I could.
Project
Here’s a link to the bot started at 5:45PM (NYC time) on 18 October 20.
There should be enough products to get us to 2021!
Enjoy.