Overview
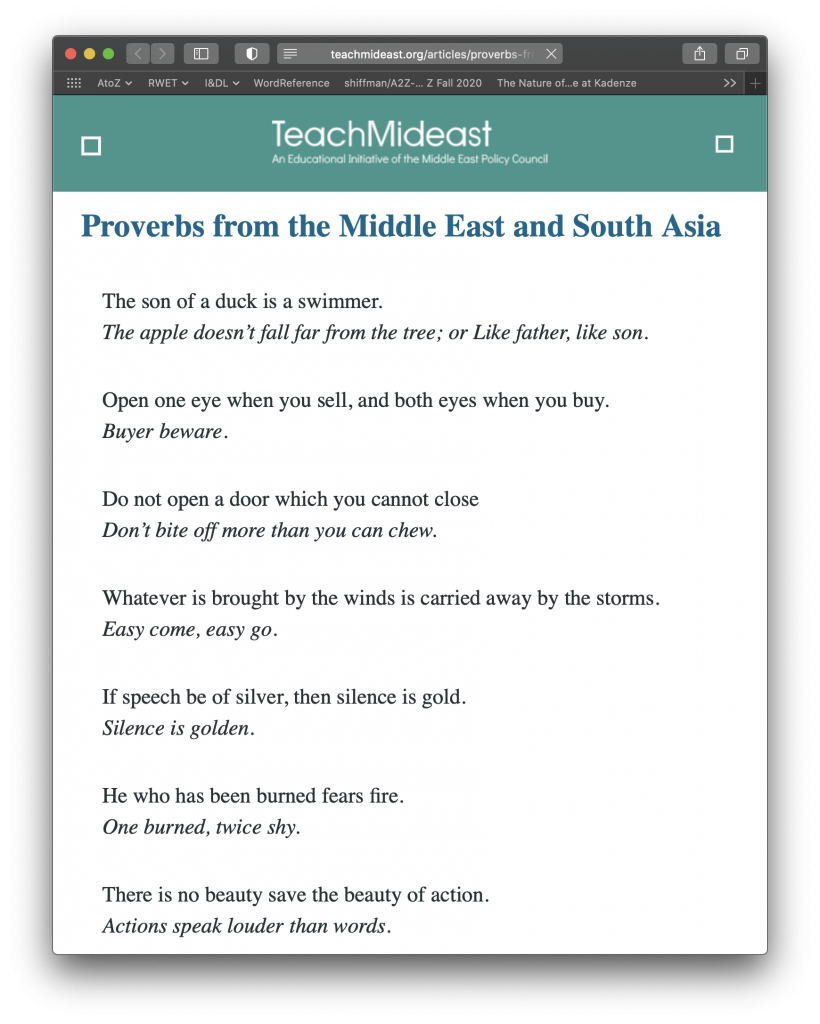
For this project, we were asked to work with Markov chains to generate text using our own data inputs. For mine, I chose to pick contrasting material that was culturally loaded to make side by side comparisons. To do this, I took a list of Eastern proverbs and their corresponding (as much as possible) Western proverbs, which I found on TeachMideast and used in my project, “Where Are You?” last semester for Electronic Rituals, Oracles, and Fortune Telling.
In terms of configuration, I loaded two text files, one with Eastern proverbs and another with Western proverbs; the files contain parallel materials. By this I mean, the first item (proverb) in the Eastern proverbs file corresponds in meaning to the first item in the Western proverbs file. In each file, there are 26 proverbs.
I’ve configured the code so that when the function running the code is called, it brings the root ngram chain (the beginning part of the text that inspires the rest of the results) that is called from the same line in each array, so at least in the very beginning, the dual ‘perverbs’ (cross between perverted and proverbs) start out with similar intention or sentiment.
As far as the nitty gritty code details go, I used 4 for my ngram length–used because it produced the most aesthetically similar appearance to what the source data was, and 50 as my max output length, for a similar reason.
Here is my project, “Perverbs – Ramblings of the Old – East & West”. (If you’d like to check out and play with the code, or even just see the input proverbs I used for my ‘perverbs’, click here for the code info.)
Motivation and Reflection
I think using Markov chains with text is fun. It produces some very interesting results that can be both exciting and confusing at the same time. Here’s a really good source that I looked at and played with for quite a bit before starting, as it provides a good explanation of how Markov chains work using physical representation.

I guess I didn’t realize how powerful Markov chains really are, though. I texted the Markov site above to my father, who’s been a programmer since learning Fortran in the Army in the early 70s. I wasn’t sure if he’d played around with them—especially since my association with Markov chains is with poetry and words. His reply really surprised me.
He wrote me back about using Markov state transition matrices way back in the late 70s in war gaming models for successful target probabilities based on decade-old research. He worked on replacing that model with a more realistic one that incorporated atmospheric conditions, line of sight computations, and target energy emissions to determine that probability more accurately. He said Markov chains can still be fairly good predictors if you have really large datasets.
Hmmm. War games. Maybe this was MUCH more powerful stuff than I’d realized. Because of this, I wanted to produce something that would be more than just simply fun surprises (which I hoped would arise, as well.) This lead me thinking of themes from which I could pull texts to juxtapose—war reporting vs peace rally coverage, love letters vs hate-mail, the Bible vs SPAM.

In this process, I was reminded of a lesson that come to mind often. Many years ago, I had a lecture where the professor was talking about assumptions we make about others. He mentioned that proverbs are one way to learn about differences in culture, as they hold within deep societal beliefs—whether implicit or explicit—and Eastern vs Western (also referred to in some languages as ‘Oriental’ vs ‘Occidental’) perspectives on the same thing can vary greatly.
For example, in the West, we say, “The squeaky wheel gets the grease.” In the East, they say, “The nail that sticks out gets hammered down.” Wow, right?! I thought using a source of such material could provide for some nice comparisons. Having done research on this subject, I thought I should pull on my previous work and pop in some of the expressions to see how what I’d get out. I was happy with the results!

As far as Emily Martinez’ questions related to working with a corpus of text data go, I made sure to read them before I sat down to work on this. For me, keeping things in mind definitely influences my development process. In terms of the questions, it wasn’t so much one question called out to me most, but the themes of ‘Responsibility’ and ‘Appropriation’ and ‘Respect’ really stuck with me in my mind as I worked.
For this project, I tried to show my respect for the source data (and the receiver of the new data) by explaining not only my process, but what my reasoning and inspiration were by documenting them (in this post.) I feel like it’s not only the responsibility of the person creating such a project to explain such logic and motivation, but it helps create clear distinctions between a project’s components (allowing them to have their own identities and sources—in doing so, the appropriation aspect can be addressed.

In more visual ways, I took the themes from Emily’s questions and tried applying them to my design process. For example, when you click the “Tell Me Something New” button, two boxes will appear. On top, is a black box with white text generated from the Eastern proverbs source file and, on the bottom, is a white box with black text generated from the Western proverbs source file. I felt like color was the only place I wanted to really contrast differences, mainly for ease of reading and identification, and I left the formatting, the font, and the input and output lengths/factors the same.
Ultimately, the original source material not only came from humans in the sense it was typed and curated, but it came from humans’ actions, observations, and reflection; because of this, I didn’t want my project to be about highlighting differences, but about bringing together different cultural perspectives where they can be appreciated side-by-side, albeit in a weird (and probably heretical) way. At the end of the day, we may all hold different perspectives, but we share much more in common, starting with our DNA.
Again, I’m really happy with the output of this project. I hope you enjoy it as well!
Un Segundo… ¿Hablas Español?
So, I was talking to my madre in Spain (I was an exchange student in the Canaries over 25 years ago and my familia still has a room in their home for me) about Markov chains and started thinking about how they might look in Spanish.

My madre said she’d be interested in what it looked like, especially since she didn’t really get my verbal explanation of Markov chains. (Not surprised, I butchered the topic.) She was very impressed by the power of code to create my Twitter bot, so I told her I’d try to track down some text in Spanish and see what came out.

Here are some screen shots of what it looked like when I put the preface and first chapter in. I ended up putting all of Don Quixote in Spanish as the text source using Dan’s example for Markov chains by letter, so if you’d like to see it and play around with that, here it is.

I found that using ngrams around 4 to 6 gave good results. Using 2 gave a lot of gibberish and using more than 10 returned more shorter results. I was expecting the ngram of 2 to give a lot more shorter words considering all the vowels in Spanish. And, many words and conjugations end in ‘a’ or ‘o’, so ‘a’+’ ‘(space) or ‘o’+’ ‘(space) I thought would be so common. I figured it would return those (‘a ‘ & ‘o ‘) as an option so often when ‘a’ or ‘o’ was called (thus making the word end in a space.) There were (or seemed to be) more shorter words, but it wasn’t like what I’d expected. Check it out above or right here below, currently the Markov chains are set to work with tetragrams (ngram = 4.)
¡Qué aproveches!